Authors:
- Yuan Tang: Project Lead, KServe; Senior Principal Software Engineer, Red Hat
- Scott Cabrinha: Staff Site Reliability Engineer, Tesla
- Robert Shaw: Director of Engineering, Red Hat
- Sai Krishna: Staff Software Engineer, Tesla
Originally posted on llm-d Blog and on KServe Blog.
The Problem with “Simple” LLM Deployments
Deploying large language models is becoming common, but the real difficulty lies in managing hundreds of LLMs efficiently at scale. Our initial approach—a straightforward vLLM deployment wrapped in Kubernetes StatefulSet—created three major operational challenges:
-
Storage Performance Issues: Large models like Llama 3 exceed hundreds of gigabytes. Network storage solutions proved impractical due to sluggish performance with massive safetensors files.
-
Infrastructure Constraints: Local LVM persistent volumes resolved speed issues but introduced rigid node-to-pod affinity requirements. Hardware failures necessitated manual intervention to delete Persistent Volume Claims and reschedule pods—an unacceptable operational burden.
-
Inefficient Load Balancing: Simple round-robin strategies fail to leverage the KV-cache on GPUs, a critical vLLM feature that maximizes throughput. Given GPU cost sensitivity, optimizing efficiency is non-negotiable.
What We Needed from an Operator
The team identified specific requirements for a Kubernetes Operator designed for AI/ML workloads:
- Full specification-level customization beyond typical Custom Resource capabilities
- Flexible deployment patterns rather than rigid prefill/decode architectures
- Integration with standard Kubernetes APIs rather than novel abstraction layers
The Winning Combination: KServe + llm-d + vLLM
The solution combined three technologies: llm-d (powered by KServe and its Inference Gateway Extension), Envoy, and Envoy AI Gateway.
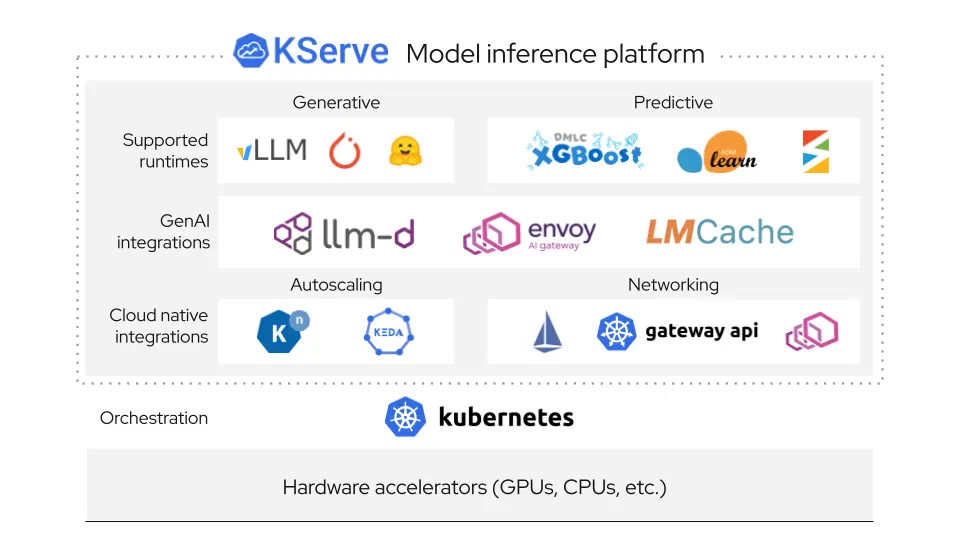
Key advantages delivered:
-
Deep Customization: LLMInferenceService and LLMInferenceConfig objects expose standard Kubernetes APIs, enabling precise specification overrides for specialized hardware and rapid flag implementation.
-
Intelligent Routing: Integration of Envoy, Envoy AI Gateway, and Gateway API Inference Extension enables “prefix-cache aware routing.” This directs requests to appropriate vLLM instances, maximizing KV-cache utilization and GPU efficiency.
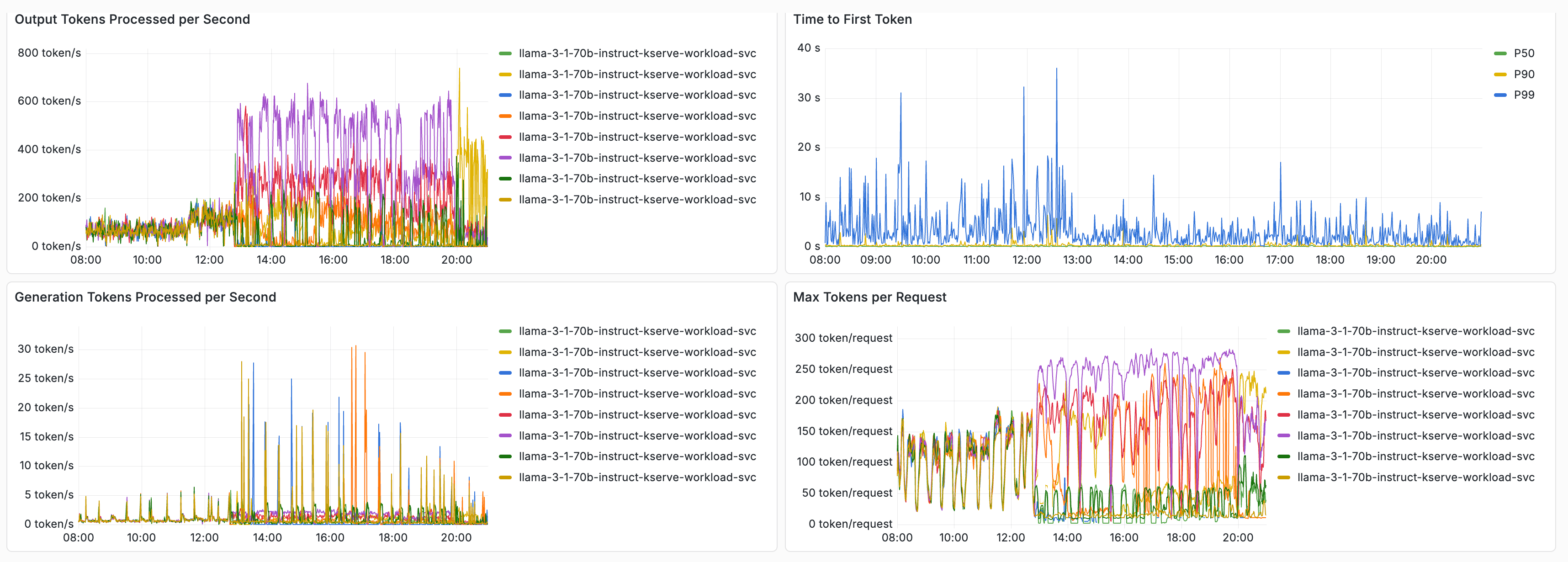
Performance Results:
Testing with Llama 3.1 70B on 4 MI300X AMD GPUs (tensor-parallel-size=4, gpu-memory-utilization=0.90, max-model-len=65536) showed:
- 3x improvement in output tokens/second
- 2x reduction in time to first token (TTFT)
These improvements occurred after enabling prefix-cache aware routing.
Community Contributions and Collaboration
Production deployment surfaced issues fixed upstream in KServe, benefiting the broader community:
- New feature requests: Issues #4901, #4900, #4898, #4899
- Made storageInitializer optional (kserve#4970) — allowing RunAI Model Streamer as an alternative to default storage initialization
- Added support for latest Gateway API Inference Extension (kserve#4886)
These contributions emerged directly from encountering production edge cases, with validation of KServe and llm-d at scale helping strengthen the platform for all Kubernetes LLM workloads.
Acknowledgement
We’d like to thank the following community contributors from Red Hat and Tesla:
Red Hat: Sergey Bekkerman, Nati Fridman, Killian Golds, Andres Llausas, Bartosz Majsak, Greg Pereira, Pierangelo Di Pilato, Ran Pollak, Vivek Karunai Kiri Ragavan, Robert Shaw, Yuan Tang
Tesla: Scott Cabrinha, Sai Krishna
Get Involved with llm-d
- Explore code at the GitHub organization
- Join the Slack community for direct maintainer contact
- Attend open community calls (Wednesdays 12:30pm ET)
- Follow project updates on Twitter/X, Bluesky, and LinkedIn
- Watch demos on the llm-d YouTube channel
- Review documentation on the community page