Authors: Yuan Tang (Red Hat) and Ashwin Bharambe (Meta)
Originally posted on vLLM blog.
We are excited to announce that vLLM inference provider is now available in Llama Stack through the collaboration between the Red Hat AI Engineering team and the Llama Stack team from Meta. This article provides an introduction to this integration and a tutorial to help you get started using it locally or deploying it in a Kubernetes cluster.
What is Llama Stack?
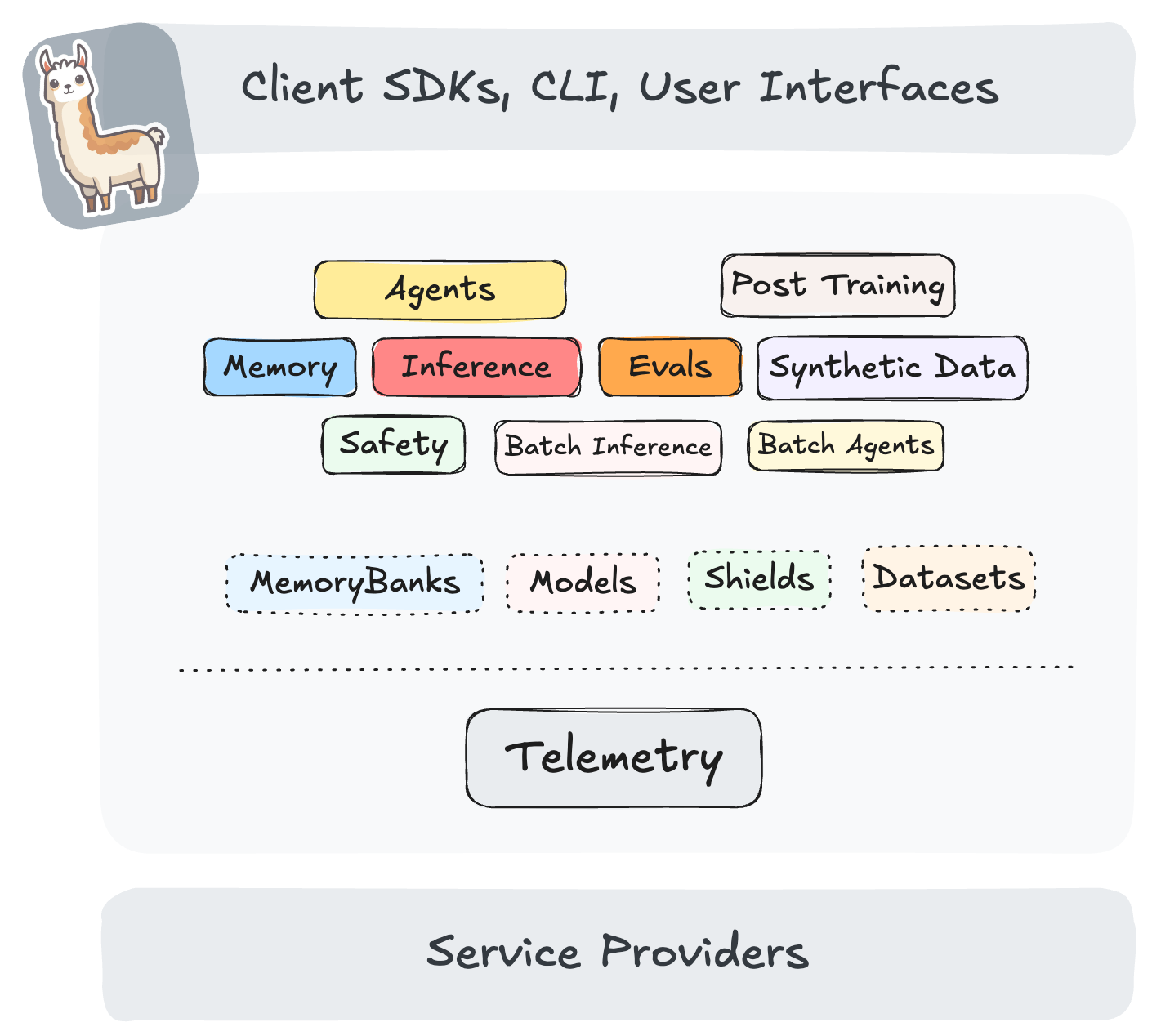
Llama Stack defines and standardizes the set of core building blocks needed to bring generative AI applications to market. These building blocks are presented in the form of interoperable APIs with a broad set of Service Providers providing their implementations.
Llama Stack focuses on making it easy to build production applications with a variety of models - ranging from the latest Llama 3.3 model to specialized models like Llama Guard for safety and other models. The goal is to provide pre-packaged implementations (aka “distributions”) which can be run in a variety of deployment environments. The Stack can assist you in your entire app development lifecycle - start iterating on local, mobile or desktop and seamlessly transition to on-prem or public cloud deployments. At every point in this transition, the same set of APIs and the same developer experience are available.
Each specific implementation of an API is called a “Provider” in this architecture. Users can swap providers via configuration. vLLM is a prominent example of a high-performance API backing the inference API.
vLLM Inference Provider
Llama Stack provides two vLLM inference providers:
- Remote vLLM inference provider through vLLM’s OpenAI-compatible server;
- Inline vLLM inference provider that runs alongside with Llama Stack server.
In this article, we will demonstrate the functionality through the remote vLLM inference provider.
Tutorial
Prerequisites
- Linux operating system
- Hugging Face CLI if you’d like to download the model via CLI.
- OCI-compliant container technologies like Podman or Docker (can be specified via the
CONTAINER_BINARYenvironment variable when runningllama stackCLI commands). - Kind for Kubernetes deployment.
- Conda for managing Python environment.
Get Started via Containers
Start vLLM Server
We first download the “Llama-3.2-1B-Instruct” model using the Hugging Face CLI. Note that you’ll need to request for access and then specify your Hugging Face token when logging in.
mkdir /tmp/test-vllm-llama-stack
huggingface-cli login --token <YOUR-HF-TOKEN>
huggingface-cli download meta-llama/Llama-3.2-1B-Instruct --local-dir /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct
Next, let’s build the vLLM CPU container image from source. Note that while we use it for demonstration purposes, there are plenty of other images available for different hardware and architectures.
git clone git@github.com:vllm-project/vllm.git /tmp/test-vllm-llama-stack
cd /tmp/test-vllm-llama-stack/vllm
podman build -f Dockerfile.cpu -t vllm-cpu-env --shm-size=4g .
We can then start the vLLM container:
podman run -it --network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct:/app/model \
--entrypoint='["python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "/app/model", "--served-model-name", "meta-llama/Llama-3.2-1B-Instruct", "--port", "8000"]' \
vllm-cpu-env
We can get a list of models and test a prompt once the model server has started:
curl http://localhost:8000/v1/models
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3.2-1B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
Start Llama Stack Server
Once we verify that the vLLM server has started successfully and is able to serve requests, we can then build and start the Llama Stack server.
First, we clone the Llama Stack source code and create a Conda environment that includes all the dependencies:
git clone git@github.com:meta-llama/llama-stack.git /tmp/test-vllm-llama-stack/llama-stack
cd /tmp/test-vllm-llama-stack/llama-stack
conda create -n stack python=3.10
conda activate stack
pip install .
Next, we build the container image with llama stack build:
cat > /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml << "EOF"
name: vllm
distribution_spec:
description: Like local, but use vLLM for running LLM inference
providers:
inference: remote::vllm
safety: inline::llama-guard
agents: inline::meta-reference
vector_io: inline::faiss
datasetio: inline::localfs
scoring: inline::basic
eval: inline::meta-reference
post_training: inline::torchtune
telemetry: inline::meta-reference
image_type: container
EOF
export CONTAINER_BINARY=podman
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack build --config /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml --image-name distribution-myenv
Once the container image has been built successfully, we can then edit the generated vllm-run.yaml to be /tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml with the following change in the models field:
models:
- metadata: {}
model_id: ${env.INFERENCE_MODEL}
provider_id: vllm
provider_model_id: null
Then we can start the Llama Stack Server with the image we built via llama stack run:
export INFERENCE_ADDR=host.containers.internal
export INFERENCE_PORT=8000
export INFERENCE_MODEL=meta-llama/Llama-3.2-1B-Instruct
export LLAMA_STACK_PORT=5000
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack run \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
/tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml
Alternatively, we can run the following podman run command instead:
podman run --security-opt label=disable -it --network host -v /tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml:/app/config.yaml -v /tmp/test-vllm-llama-stack/llama-stack:/app/llama-stack-source \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
--entrypoint='["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]' \
localhost/distribution-myenv:dev
Once we start the Llama Stack server successfully, we can then start testing a inference request:
Via Bash:
llama-stack-client --endpoint http://localhost:5000 inference chat-completion --message "hello, what model are you?"
Output:
ChatCompletionResponse(
completion_message=CompletionMessage(
content="Hello! I'm an AI, a conversational AI model. I'm a type of computer program designed to understand and respond to human language. My creators have
trained me on a vast amount of text data, allowing me to generate human-like responses to a wide range of questions and topics. I'm here to help answer any question you
may have, so feel free to ask me anything!",
role='assistant',
stop_reason='end_of_turn',
tool_calls=[]
),
logprobs=None
)
Via Python:
import os
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url=f"http://localhost:{os.environ['LLAMA_STACK_PORT']}")
# List available models
models = client.models.list()
print(models)
response = client.inference.chat_completion(
model_id=os.environ["INFERENCE_MODEL"],
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about coding"}
]
)
print(response.completion_message.content)
Output:
[Model(identifier='meta-llama/Llama-3.2-1B-Instruct', metadata={}, api_model_type='llm', provider_id='vllm', provider_resource_id='meta-llama/Llama-3.2-1B-Instruct', type='model', model_type='llm')]
Here is a haiku about coding:
Columns of code flow
Logic codes the endless night
Tech's silent dawn rise
Deployment on Kubernetes
Instead of starting the Llama Stack and vLLM servers locally. We can deploy them in a Kubernetes cluster. We’ll use a local Kind cluster for demonstration purposes:
kind create cluster --image kindest/node:v1.32.0 --name llama-stack-test
Start vLLM server as a Kubernetes Pod and Service (remember to replace <YOUR-HF-TOKEN> with your actual token):
cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Secret
metadata:
name: hf-token-secret
type: Opaque
data:
token: "<YOUR-HF-TOKEN>"
---
apiVersion: v1
kind: Pod
metadata:
name: vllm-server
labels:
app: vllm
spec:
containers:
- name: llama-stack
image: localhost/vllm-cpu-env:latest
command:
- bash
- -c
- |
MODEL="meta-llama/Llama-3.2-1B-Instruct"
MODEL_PATH=/app/model/$(basename $MODEL)
huggingface-cli login --token $HUGGING_FACE_HUB_TOKEN
huggingface-cli download $MODEL --local-dir $MODEL_PATH --cache-dir $MODEL_PATH
python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH --served-model-name $MODEL --port 8000
ports:
- containerPort: 8000
volumeMounts:
- name: llama-storage
mountPath: /app/model
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: vllm-models
---
apiVersion: v1
kind: Service
metadata:
name: vllm-server
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
type: NodePort
EOF
We can verify that the vLLM server has started successfully via the logs (this might take a couple of minutes to download the model):
$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Then we can modify the previously created vllm-llama-stack-run.yaml to /tmp/test-vllm-llama-stack/vllm-llama-stack-run-k8s.yaml with the following inference provider:
providers:
inference:
- provider_id: vllm
provider_type: remote::vllm
config:
url: http://vllm-server.default.svc.cluster.local:8000/v1
max_tokens: 4096
api_token: fake
Once we have defined the run configuration for Llama Stack, we can build an image with that configuration and the server source code:
cat >/tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s <<EOF
FROM distribution-myenv:dev
RUN apt-get update && apt-get install -y git
RUN git clone https://github.com/meta-llama/llama-stack.git /app/llama-stack-source
ADD ./vllm-llama-stack-run-k8s.yaml /app/config.yaml
EOF
podman build -f /tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s -t llama-stack-run-k8s /tmp/test-vllm-llama-stack
We can then start the Llama Stack server by deploying a Kubernetes Pod and Service:
cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llama-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: llama-stack-pod
labels:
app: llama-stack
spec:
containers:
- name: llama-stack
image: localhost/llama-stack-run-k8s:latest
imagePullPolicy: IfNotPresent
command: ["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]
ports:
- containerPort: 5000
volumeMounts:
- name: llama-storage
mountPath: /root/.llama
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: llama-pvc
---
apiVersion: v1
kind: Service
metadata:
name: llama-stack-service
spec:
selector:
app: llama-stack
ports:
- protocol: TCP
port: 5000
targetPort: 5000
type: ClusterIP
EOF
We can check that the Llama Stack server has started:
$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: ASGI 'lifespan' protocol appears unsupported.
INFO: Application startup complete.
INFO: Uvicorn running on http://['::', '0.0.0.0']:5000 (Press CTRL+C to quit)
Now let’s forward the Kubernetes service to a local port and test some inference requests against it via the Llama Stack Client:
kubectl port-forward service/llama-stack-service 5000:5000
llama-stack-client --endpoint http://localhost:5000 inference chat-completion --message "hello, what model are you?"
You can learn more about different providers and functionalities of Llama Stack on the official documentation.
Acknowledgement
We’d like to thank the Red Hat AI Engineering team for the implementation of the vLLM inference providers, contributions to many bug fixes, improvements, and key design discussions. We also want to thank the Llama Stack team from Meta and the vLLM team for their timely PR reviews and bug fixes.